question
Two singly linked-lists intersect at a node and merge into a single linked-list. The size of
each is unknown and the number of nodes prior to the intersection node can vary in
each list. Devise an algorithm to find the intersecting node.
In other words, two singly linked-lists meet at some point, find the node at which they meet.
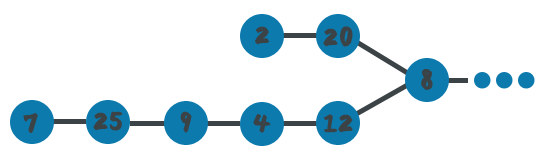
In other words, two singly linked-lists meet at some point, find the node at which they meet.
Keep in mind that after the lists merge they become the same size. Use this to your advantage.
Suppose we have two linked lists: A & B and we'll call the intersecting node I.
A naive and inefficient solution that runs in O(n2) would involve comparing each node in A to each node in B to determine the first common node.
We know that after the intersection node I, A & B will have the same size (because they merge). The following solution takes advantage of this fact and runs in O(size of A + size of B) and O(1) space.
1. Traverse through A to get its count. Let the count be cA.
2. Traverse through B to get its count. Let the count be cB.
3. Get the difference between size of the lists: d = |cA - cB|
4. Traverse through the larger list till d nodes. From here onward both lists will have equal number of nodes.
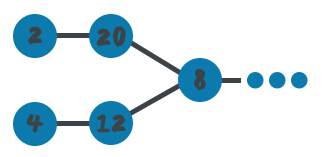
5. Traverse through both lists in parallel until you reach the intersecting node I.
Note that in comparing nodes we must compare the address of the node rather than the value to ensure correct implementation.
Check here for some alternate solutions that may be less elegant but still correct.
A naive and inefficient solution that runs in O(n2) would involve comparing each node in A to each node in B to determine the first common node.
We know that after the intersection node I, A & B will have the same size (because they merge). The following solution takes advantage of this fact and runs in O(size of A + size of B) and O(1) space.
1. Traverse through A to get its count. Let the count be cA.
2. Traverse through B to get its count. Let the count be cB.
3. Get the difference between size of the lists: d = |cA - cB|
4. Traverse through the larger list till d nodes. From here onward both lists will have equal number of nodes.
5. Traverse through both lists in parallel until you reach the intersecting node I.
Note that in comparing nodes we must compare the address of the node rather than the value to ensure correct implementation.
Check here for some alternate solutions that may be less elegant but still correct.